Kaldi Failed to Read Matrix From Stream
How to outset with Kaldi and Speech Recognition
The all-time way to attain a state of the art speech recognition system
What is Kaldi?
Kaldi is an open source toolkit made for dealing with spoken communication data. it's beingness used in voice-related applications mostly for speech recognition simply besides for other tasks — like speaker recognition and speaker diarisation. The toolkit is already pretty old (effectually seven years quondam) only is still constantly updated and further adult past a pretty large community. Kaldi is widely adopted both in Academia (400+ citations in 2015) and industry.
Kaldi is written mainly in C/C + +, but the toolkit is wrapped with Fustigate and Python scripts. For basic usage this wrapping spares the need to get in as well deep in the source code. Over the course of the last 5 months I learned about the toolkit and about using it. The goal of this article is to guide you through that process and give you the materials that helped me the well-nigh. See it as a shortcut.
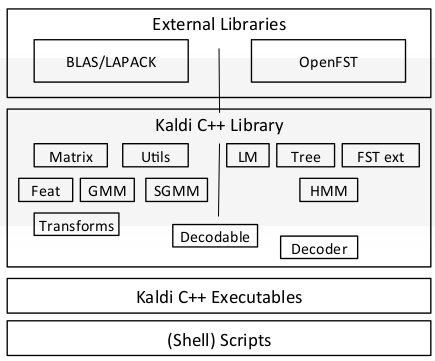
This article will include a general understanding of the training process of a Speech Recognition model in Kaldi, and some of the theoretical aspects of that process.
This article won't include code snippets and the bodily way for doing those things in exercise. For that matter you can read the "Kaldi for Dummies" tutorial or other cloth online.
MFCC stands for Mel-Frequency Cepstral Coefficients and it has get almost a standard in the industry since it was invented in the 80s past Davis and Mermelstein. You tin get a better theoretical explanation of MFCCs in this amazing readable commodity. For bones usage all you lot need to know is that MFCCs are taking into account just the sounds that are best heard past our ears.
In Kaldi nosotros use ii more than features:
- CMVNs which are used for better normalization of the MFCCs
- I-Vectors (That deserve an article of their ain) that are used for better understanding of the variances inside the domain. For example - creating a speaker dependent representation. I-Vectors are based on the same ideas of JFA (Joint Factor Analysis), but are more suitable for understanding both channel and speaker variances. The math behind I-Vectors is clearly described hither and here.
For a basic understanding of these concepts, remember the post-obit things:
- MFCC and CMVN are used for representing the content of each audio utterance.
- I-Vectors are used for representing the manner of each sound utterance or speaker.
The Model
The matrix math behind Kaldi is implemented in either BLAS and LAPACK (Written in Fortran!),or with an alternative GPU implementation based on CUDA. Because of its usage of such low-level packages, Kaldi is highly efficient in performing those tasks.
Kaldi's model tin be divided into two main components:
The first office is the Acoustic Model, which used to be a GMM just at present it was wildly replaced by Deep neural networks. That model will transcribe the audio features that we created into some sequence of context-dependent phonemes (in Kaldi dialect we call them "pdf-ids" and correspond them by numbers).
The second part is the Decoding Graph, which takes the phonemes and turns them into lattices. A lattice is a representation of the culling word-sequences that are likely for a item sound part. This is generally the output that you want to get in a spoken communication recognition organisation. The decoding graph takes into account the grammar of your data, as well as the distribution and probabilities of contiguous specific words (due north-grams).
The decoding graph is essentially a WFST and I highly encourage anyone that wants to professionalize to acquire this subject thoroughly. The easiest way to practise information technology is through those videos and this classic article. Subsequently understanding both of those you can sympathise the fashion that the decoding graph works more hands. This composition of different WFSTs is named in Kaldi project — "HCLG.fst file" and it'south based on the open-fst framework.

Worth Noticing: This is a simplification of the way that the model works. There is actually a lot of detail about connecting the two models with a decision tree and about the mode that you represent the phonemes, only this simplification can assist you to grasp this process.
You tin learn in depth about the entire compages in the original article describing Kaldi and almost the decoding graph specifically in this amazing blog .
The Preparation Process
In general, that's the trickiest part. In Kaldi yous'll demand to lodge your transcribed sound data in a really specific order that is described in depth in the documentation.
After ordering your data, you'll need a representation of each word to the phonemes that create them. This representation will exist named "lexicon" and it will determine the outputs of the acoustic model. Hither is an example of such dictionary:
viii -> ey t
five -> f ay v
four -> f ao r
nine -> n ay n
When you have both of those things at hand, you can beginning training your model. The unlike training steps you can use are named in Kaldi dialect "recipes". The virtually wildly used recipe is WSJ recipe and you can look at the run fustigate script for a better agreement of that recipe.
In most of the recipes nosotros are starting with adjustment the phonemes into the audio sound with GMM. This basic stride (named "alignment") helps u.s. to make up one's mind what is the sequence that nosotros want our DNN to spit out later.
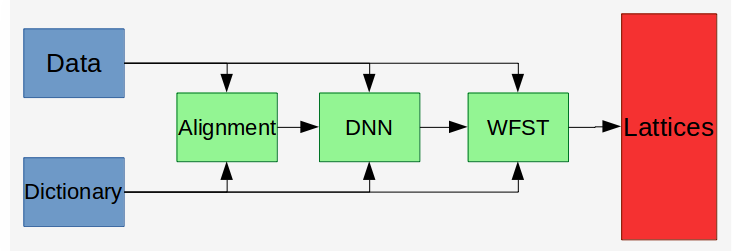
After the alignment we volition create the DNN that volition form the Acoustic Model, and we will train it to match the alignment output. After creating the acoustic model we can train the WFST to transform the DNN output into the desired lattices.
"Wow, that was cool! What can I do next?"
- Try it out.
- Read more than
How to endeavour
Download this Costless Spoken Digit Dataset, and just try to train Kaldi with it! You should probably attempt to vaguely follow this. You tin can too just utilize i of the many dissimilar recipes mentioned above.
If yous succeed, try to go more data. if you neglect, try asking questions in the Kaldi aid group.
Where to read more than
I cannot emphasize how much this 121 slides presentation helped me it'south based mostly on the series of those lectures. Another great source is everything from Josh Meyer's website. You can find those links and many more in my Github-Kaldi-awesome-list.
Try reading through the forums, effort to dig deeper into the code and effort to read more articles, I'thousand pretty certain yous will accept some fun. :)
If you accept whatsoever question fill free to enquire them here or contact me through my Email and fill costless to follow me on Twitter or on Linkedin.
Source: https://towardsdatascience.com/how-to-start-with-kaldi-and-speech-recognition-a9b7670ffff6
0 Response to "Kaldi Failed to Read Matrix From Stream"
Post a Comment